
Proving the hardness of an algorithm for non-polynomial algorithms takes skill. As we wrap up our journey of The Algorithm Design Manual we’re going to leave you with some final tips to help prove the hardness of these intractable problems. But first, onto the Daily Problem:
This article is part of the Data Structures and Algorithms Series following the course The Analysis of Algorithms. If you missed the previous article, check that out first as well as a copy of The Algorithm Design Manual.
Answers to the previous Daily Problem
Show that the following problem is NP-complete: for a graph
Gwith integerskandy, doesGcontain a dense subgraph with exactlykvertices and at leastyedges?
When I look at this problem I instantly think of the tree of reductions that we went over the last few articles. So right away I’m thinking of the graph-specific configurations: independent set, vertex cover, and clique. The key in choosing these three is in the word dense…which of the graph types in the reductions list deals with dense configurations? My first instinct is clique because of how we want every vertex to touch every other node (think back to the example of the pentagram in the pentagon).
So if we can reduce a dense subgraph into a clique via a reduction, and we know that a clique is part of the NP-complete hardness tree, then we have our solution.
A clique is a fully-connected graph. So if the dense subgraph is a subset of the connections in a clique, your dense subgraph generalizes to clique and therefore the graph is also NP-complete. This is called a K-clique densest subgraph if you want to know more about the formal proof.
Nearing the end: tips for proving hardness
We’ve come a long way in our journey in understanding data structures and algorithms. At this point we’re entering territory where programming languages no longer matter; these theoretical algorithms have no real solutions so we can’t map them to code samples. Whether you’re studying this for fun or for interviews you may reach this final stage where you need to understand how to solve for uncharted territory. Here’s a few tips on proving algorithmic hardness:
Choose a good, simple NP-hard graph
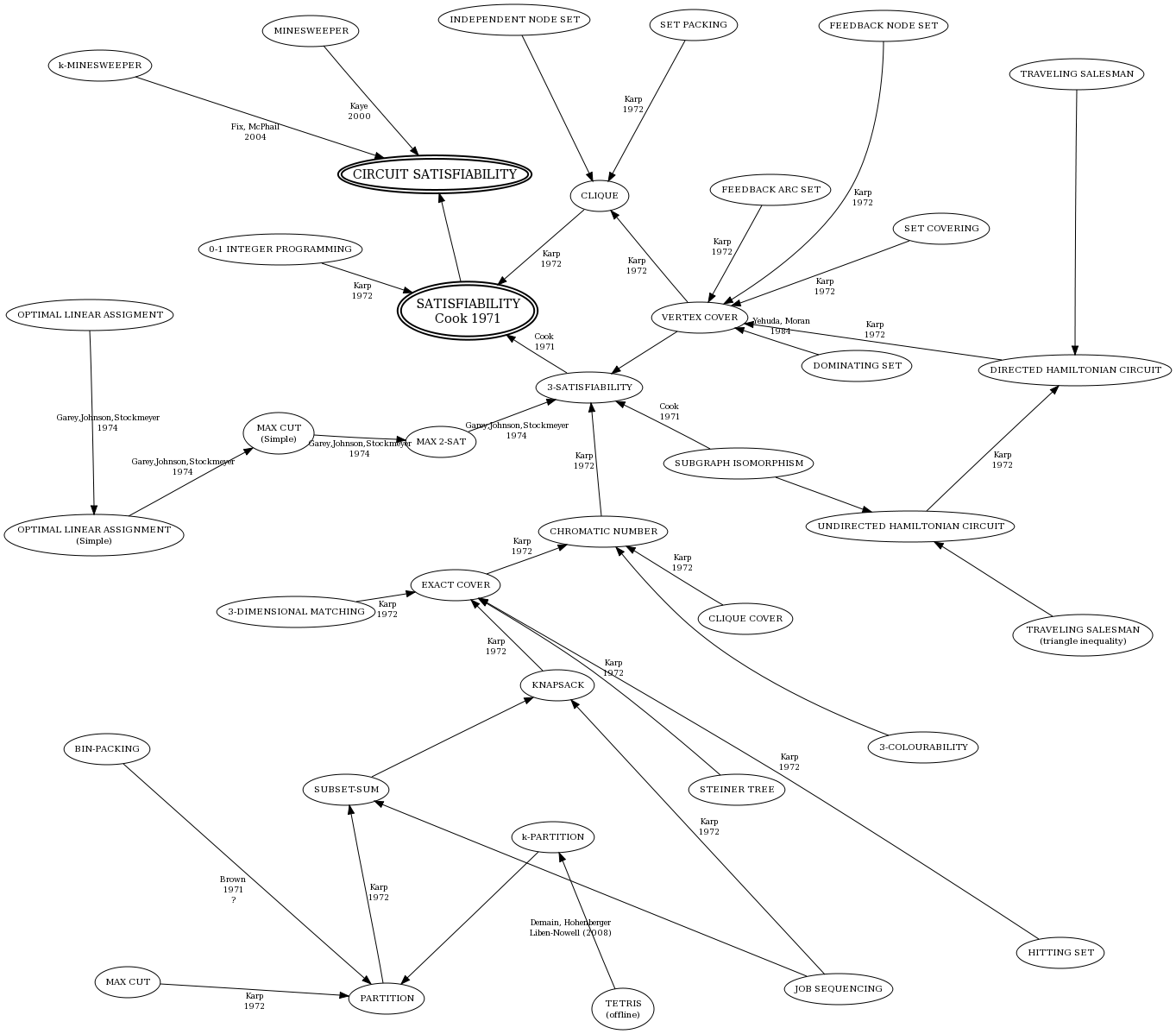
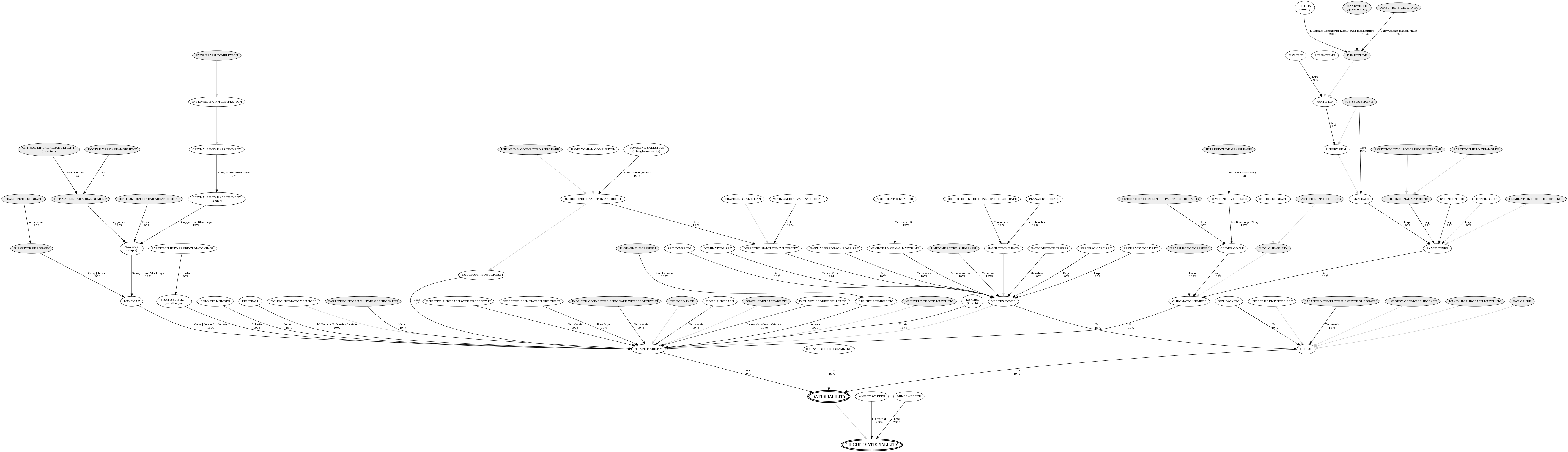
The first and most important thing is to identify the right kind of NP-complete problem. Knowing the chart of problem translations is extremely handy in these situations. Here’s a few based on how much you think you can fit in your head:
{kind=link}
{kind=link}
{kind=link}
If you look at the Daily Problem, much of the effort came down to choosing the right source problem. Clique was clearly the right choice for K-clique densest subgraph. But even then, you could still find a reduction using vertex cover or 3-SAT, it would just be harder to make the translation from the source to the destination problem. For most of these problems, you pretty much only ever need to start with 3-SAT, vertex cover, Hamiltonian path, or integer partition:
- Worried about order or scheduling like a calendar? Start with Hamiltonian path.
- Dealing with selection and filtering? Start with vertex cover, though clique and independent set are obvious offshoots if you can see the distinction.
- How about combinatorics or large numbers? Integer partition is what you want.
- For everything else? 3-SAT is at the top of the NP-complete food chain and is extremely versatile.
Constrain the problem as much as possible
Constraints are good. An undirected graph becomes a directed graph. An unweighted graph adds weights. Or we can flip it: we did this when reducing TSP into a Hamiltonian cycle by turning weighted edges into unweighted ones, equalizing the cost of each edge for a Hamiltonian cycle.
Your constraints should inject harsh penalties for deviating away from your reduction. When we reduced Integer programming into 3-SAT, the maximization function and target value all became inconsequential. To ensure we didn’t let that get in our way, we had to neutralize the maximization function to the identity function and set the target to 0. Any other set of values would make it more difficult to prove.
Once you have the constraints, force a decision. Make it so that the choice is between A or B and never A and B.
Reductions are easier than algorithms but keep your options open
When your head is in the NP-complete or NP-hard space you automatically assume that the problem is unsolveable with an algorithm. However, non-polynomial problems in the exponential space can still be solved with techniques like dynamic programming to bring it back down into efficient polynomial space.
In other cases, you can use approximation algorithms with heuristics to turn NP-hard problems into polynomial-time solutions. Maximum clique, minimum vertex cover, and the Knapsack problem all benefit from approximation algorithms to arrive at a relatively correct but efficient result.
Final thoughts
This project of auditing the class for The Algorithm Design Manual was truly a labor of love. Learning by teaching is a great way to really cement your understanding of the materials in this series.
If you used this to help you understand data structures and algorithms for an upcoming interview, I want to leave you with a selection of problems over the whole book as sort of a final exam to test your knowledge. These problems are specifically designed for those interviewing at companies, so if you can tackle these, you’ll be in a great spot. Good luck and thanks for sticking with me!
- Problem 1-29.
- Problem 1-31.
- Problem 1-33.
- Problem 2-43.
- Problem 2-45.
- Problem 2-47.
- Problem 2-49.
- Problem 2-51.
- Problem 3-19.
- Problem 3-21.
- Problem 3-23.
- Problem 3-25.
- Problem 3-27.
- Problem 3-29.
- Problem 4-41.
- Problem 4-43.
- Problem 4-45.
- Problem 5-31.
- Problem 7-15.
- Problem 7-17.
- Problem 7-19.
- Problem 8-25.
Get the FREE UI crash course
Sign up for our newsletter and receive a free UI crash course to help you build beautiful applications without needing a design background. Just enter your email below and you'll get a download link instantly.